目前我知道的三种方式:
1. 使用随机数
概述 : 这种方式相对比较原始 , 就是 更具随机的值进行 排序 , 然后 再进行 获取 前 1000 行数据 .
优点 : 随机性 好
缺点 : 性能差 (当进行获取的数据量 越大 , 执行的时间就越长 )
2. 使用sample函数
概述 : sample函数 旨在 随机样本抽取 , 但是涵盖的数据 分布 非常不均匀 .
优点 : 性能好 (执行的时间相对比较短)
缺点 : 随机性差(因为涵盖的数据分布非常不均匀)
3. 结合上述两种方式(随机数+sample函数)
概述 : 这种是先使用sample函数 抽取部分数据, 再使用随机数进行排序 .
优点 : 性能相对较好 (比方式一 性能好 , 比方式二 随机性好)
缺点 : 数据命中率不能达到 百分百 (因为使用了 sample函数 , 当数据量比较少时 , 不能保证每次都能返回 获取的样本数据 , 抽样的表不能用 dblink[数据库连接])
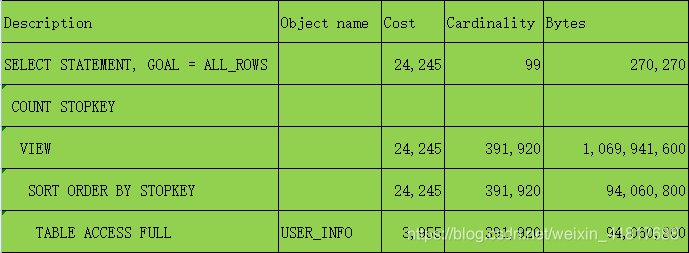
Oracle数据库:随机查询100条数据
方法一
注:USER_INFO约40w条数据.