Mysql大表数据归档
前言
在生产实践中,你的mysql数据库可能面临下面这些情况:
不可抗力的因素,数据库所在服务器被回收,或者服务器磁盘损坏,数据库必须得迁移?
单点数据库读写压力越来越大,需要扩展一个或多个节点分摊读写压力?
单表数据量太大了,需要进行水平或垂直拆分怎么搞?
数据库需要从mysql迁移到其他数据库,比如PG,OB…
以上的这些场景,对于不少同学来讲,或多或少的在所处的业务中可能会涉及到,没有碰到还好,一旦发生了这样的问题,该如何处理呢?在这里我通过提供一个思路来解决单表数据量太大了,进行水平拆分,将历史数据归档保证热点数据查询。
归档流程示意图
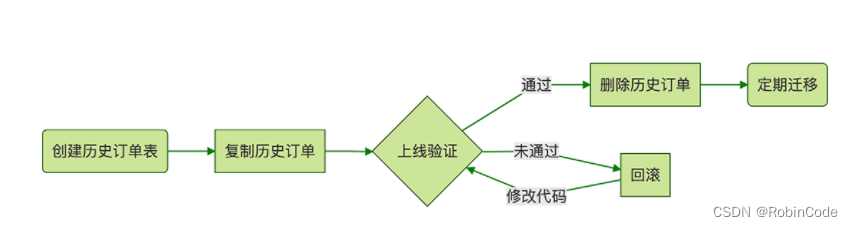
实现步骤
controller 层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | @Slf4j@RestController@RequestMapping("/backDoor")public class CleanHistoryDataController { @Autowired private ICleanHistoryDataService cleanHistoryDataService; /** * 把指定过期时间的订单表数据迁移到历史表中 */ @PostMapping("/cleanByTableNameAndEndTime") public Resp<String> cleanByTableNameAndEndTime(@RequestBody CleanTableReq cleanTableReq) { try { CleanTableBo cleanTableBo = ObjectUtils.mapValue(cleanTableReq, CleanTableBo.class); cleanHistoryDataService.cleanByTableNameAndEndTime(cleanTableBo); } catch (Exception e) { log.error(cleanTableReq.getTableName() + " 数据迁移异常", e); } return Resp.success("success"); }} |
Service 层
1 2 3 4 | public interface ICleanHistoryDataService { void cleanHistoryTableData();} |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | import com.alibaba.fastjson.JSONObject;import com.photon.union.risk.clean.service.ICleanHistoryDataService;import com.photon.union.risk.repo.mapper.clean.MasterDbMapper;import lombok.extern.slf4j.Slf4j;import org.apache.commons.collections4.CollectionUtils;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import org.springframework.util.StopWatch;import java.util.List;import java.util.stream.Collectors;/** * @author robin */@Service@Slf4jpublic class CleanHistoryDataService implements ICleanHistoryDataService { @Autowired private MasterDbMapper masterDbMapper; @Override public void cleanHistoryTableData() { StopWatch stopWatch = new StopWatch(); stopWatch.start(); int logInt = 0; Long startId = 0L; while (true) { logInt ++; List<JSONObject> hashMapList = masterDbMapper.selectHistoryTableDataIds(startId); if (CollectionUtils.isEmpty(hashMapList)){ break; } List<Long> allIds = hashMapList.stream().map(o -> o.getLong("id")).collect(Collectors.toList()); startId = allIds.get(allIds.size()-1); if (logInt % 100 == 0 ){ log.info("id 已经处理到-->" + allIds.get(allIds.size()-1)); } try { // 往归档历史数据表写入数据 masterDbMapper.insertOldHistoryTableDataBatchByIds(allIds); // 把归档的数据从目前业务表中删除 masterDbMapper.deleteHistoryTableDataBatchByIds(allIds); }catch (Exception e){ log.error("数据迁移异常,ids:{}", allIds, e); } } stopWatch.stop(); log.info("数据迁移到历史表处理完成时间:{}s", (long)stopWatch.getTotalTimeSeconds()); }} |
Mapper 层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import com.alibaba.fastjson.JSONObject;import org.apache.ibatis.annotations.Param;import org.springframework.stereotype.Repository;import java.util.List;/** * @author robin */@Repositorypublic interface MasterDbMapper { List<JSONObject> selectHistoryTableDataIds( @Param("id") Long startId); void insertOldHistoryTableDataBatchByIds(@Param("ids") List<Long> allIds); void deleteHistoryTableDataBatchByIds(@Param("ids") List<Long> allIds);} |
Sql Mapper
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | <?xml version="1.0" encoding="UTF-8"?><!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.test.MasterDbMapper"> <insert id="insertOldHistoryTableDataBatchByIds"> INSERT IGNORE INTO t_order_old SELECT NULL,order_no,created_at FROM t_order WHERE id in <foreach collection="ids" item="item" open="(" close=")" separator=","> #{item} </foreach> </insert> <delete id="deleteHistoryTableDataBatchByIds"> DELETE FROM t_order WHERE id IN <foreach collection="ids" item="item" open="(" close=")" separator=","> #{item} </foreach> </delete> <select id="selectHistoryTableDataIds" resultType="com.alibaba.fastjson.JSONObject"> SELECT id FROM t_order WHERE id > #{id} and created_at lt;= DATE_SUB(NOW(), INTERVAL 6 MONTH) ORDER BY id limit 1000 </select></mapper> |
核心说明
根据 t_order订单表结构创建 t_order_old历史订单表用于历史数据备份存放。
整个流程基于主键 id 处理,避免慢 sql 产生,做到不影响当前线上业务处理。
1000 条记录一个批次,避免长期抢占锁资源,同时每个批次执行不影响下个批次处理,出现异常后,打印 error 日志再人工跟进处理。